Benchmark Overview
The first systematic evaluation of subjective writing preference across cultures
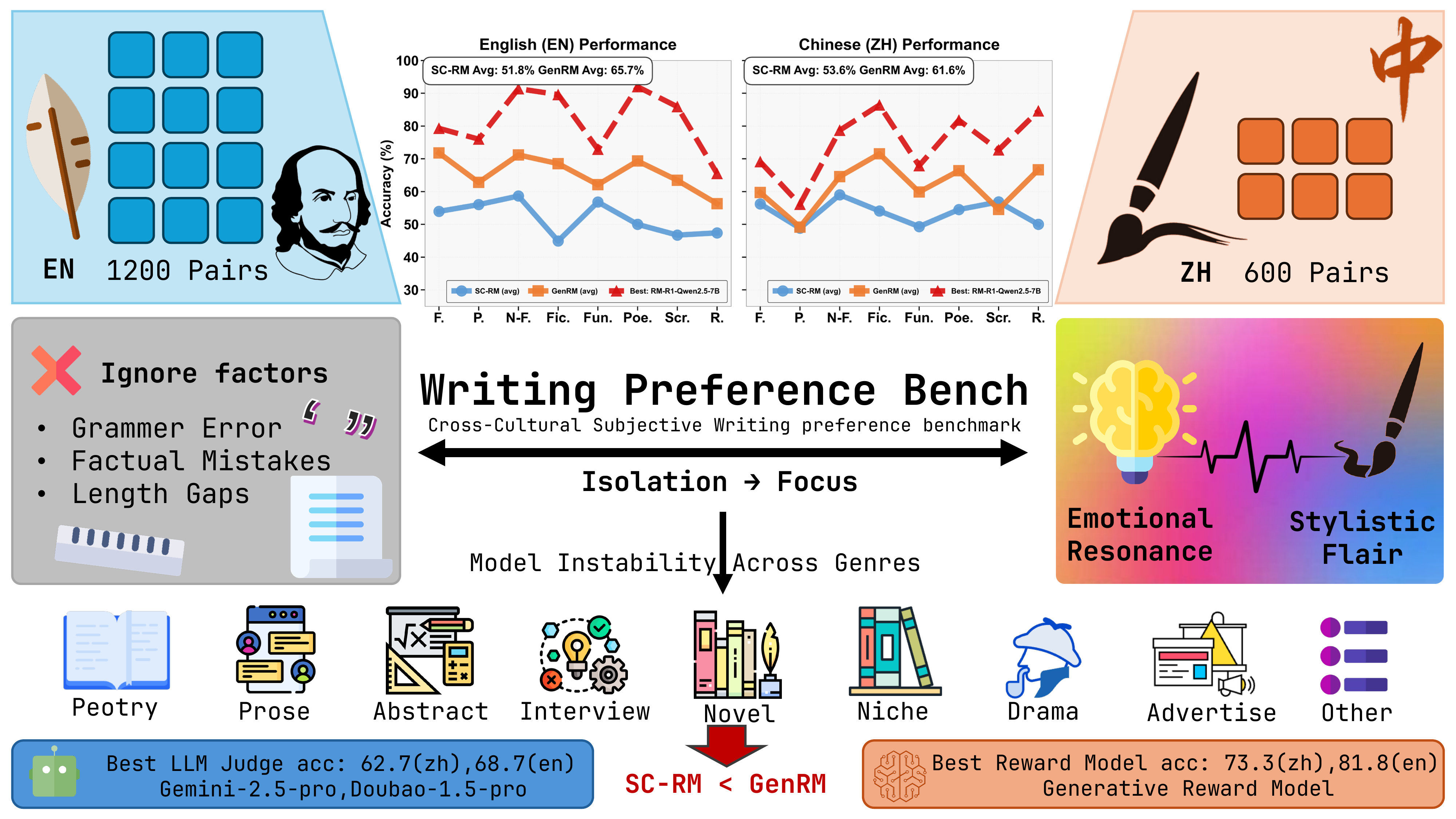
Current preference learning methods achieve high accuracy on standard benchmarks but exhibit significant performance degradation when objective quality signals are removed. We introduce WritingPreferenceBench, a dataset of 1,800 human-annotated preference pairs (1,200 English, 600 Chinese) across 8 creative writing genres, where responses are matched for objective correctness, factual accuracy, and length.
On this benchmark, sequence-based reward models—the standard architecture for RLHF—achieve only 52.7% mean accuracy, while zero-shot language model judges perform at 53.9%. In contrast, generative reward models that produce explicit reasoning chains achieve 81.8% accuracy. We observe high within-model variance across genres: individual models range from 18.2% to 81.8% accuracy across different writing categories, with standard deviations averaging 10.1%.
This variance persists regardless of model scale, with 27B parameter models showing no consistent improvement over 8B variants. Our results suggest that current RLHF methods primarily learn to detect objective errors rather than capture subjective quality preferences (e.g., creativity, stylistic flair, and emotional resonance), and that successful preference modeling may require intermediate reasoning representations rather than direct classification.
Key Findings
Revealing the catastrophic failure of current RLHF architectures on subjective tasks
Sequence Classifiers
Standard RLHF architectures perform near-randomly on subjective preference tasks when objective signals are removed
Generative Reward Models
Models with explicit reasoning chains achieve 29 percentage points higher accuracy than sequence classifiers
Genre Instability
Mean standard deviation across genres reveals severe brittleness, with individual models ranging from 18.2% to 92.0% accuracy
LLM Judges
Zero-shot language models systematically underperform specialized reward models despite orders of magnitude more parameters
The Core Discovery
WritingPreferenceBench reveals the catastrophic failure of current RLHF architectures
Model Performance Breakdown
Comprehensive comparison across architectures and model scales
| Model | Architecture | Scale | EN Acc | ZH Acc | Variance | Best Genre | Worst Genre |
|---|---|---|---|---|---|---|---|
| RM-R1-Qwen2.5-7B | Generative | 7B | 81.8% | 73.3% | 10.2% | Poetry (92%) | Promo (56%) |
| RM-R1-DeepSeek-14B | Generative | 14B | 62.5% | 62.6% | 5.5% | Poetry (90%) | Promo (46%) |
| RM-Mistral-7B | Sequence | 7B | 62.6% | 55.6% | 9.6% | Script (78%) | RP (45%) |
| Skywork-Gemma-27B | Sequence | 27B | 46.8% | 51.2% | 11.9% | Poetry (82%) | Script (22%) |
| Nvidia/AceMath-7B | Sequence | 7B | 46.8% | 53.5% | 11.8% | RP (62%) | Poetry (18%) |
| Model | Type | EN Acc | ZH Acc | Variance | Best Genre | Worst Genre |
|---|---|---|---|---|---|---|
| Doubao-1.5-Pro | Standard | 68.7% | 62.5% | 9.0% | Promo (75%) | Promo (48%) |
| Gemini-2.5-Pro | Standard | 65.7% | 62.7% | 11.9% | Poetry (80%) | Script (35%) |
| Claude-4-Opus-thinking | Reasoning | 61.0% | 56.0% | 9.7% | Fiction (73%) | Promo (36%) |
| DeepSeek-R1 | Reasoning | 49.3% | 52.0% | 12.1% | Poetry (72%) | Script (17%) |
| OpenAI-o3-high | Reasoning | 48.1% | 42.0% | 12.5% | Poetry (72%) | Script (22%) |
Methodology
Rigorous human-in-the-loop pipeline ensures reliable subjective preference isolation
Signal Neutralization
Systematic removal of objective quality signals (grammar, factuality, length) through automated filtering and human validation to isolate pure subjective preference
Expert Annotation
11 expert annotators with professional writing backgrounds using calibrated 4-point creativity scale across universal and genre-specific quality criteria
Cross-Cultural Validation
Bilingual dataset construction with equivalent methodological standards applied across English and Chinese literary contexts
Comprehensive Evaluation
Systematic assessment of 21 state-of-the-art models across reward models, LLM judges, and reasoning-enhanced variants
Interactive Demo
Explore sample preference pairs from our dataset
Select Genre
Sample Preference Pair - Fiction
Citation
Reference this work in your research